
Mobility
has to be embraced by the Financial Services Providers (FSPs) is clear to all.
The big questions are how, when and for what services. This article gives some
broad analysis to address these questions. The findings are that financial
Information based services should be embraced immediately; the transactional
services should be the medium term goal, i.e., within 6 months to a year, and
finally by 2003 FSPs need to embrace the full customer relationship including
one-click transaction, live advice, personal mobile Ads, and third party
sales.
The Financial Services Providers (FSP) including banks,
Investment institutions, Insurance firms, etc, will have to adopt their
offerings to the new channel to take care of the uncertain future. Although the
immediate benefits of the technology may not look much due to various security
related and other issues, however, the potential that mobile access offers is
so great that FSPs will be forced to embrace it. Despite the initial reluctance
in adoption of the technology, the FSPs will have to follow a new multi-
platform strategy in offering their services. The reasons for the shift are not
hard to assess.
Instead of waiting for technologies to stabilize and giving mobile
delight to customers, it makes sense to deploy mobile applications now.
Mobile Access to Internet is increasing rapidly,
in general. Enterprises are already making plans to invest in mobile
technologies for mobile enabling their employees and customers for
business purposes. This will accelerate the demand for financial services on
mobile devices

The FSPs who start these services first will have the
advantage. Rather than waiting for conceptualizing a Killer Application,
it would be better to adapt to wireless within the constraints of the
technology. Besides the first mover advantage, this offers an experience with a
technology that is continuously happening and will be improving- if we go by the new evolving networks based on
increasingly powerful industry standards of GPRS, EDGE and UMTS. These are
leading to next generation of wireless networks called 3G, which can provide up
to 2 Mbps bandwidth. Hence, instead of waiting for technologies to stabilize
and then giving mobile delight to customers, it makes sense to deploy mobile
applications now.
Financial Services
Financial services can be segmented into Retail Banking, Retail
Broking, Investment Banking and Mobile
payments. Beside these FSP may be providing services related to Insurance,
Financial advising, Loans, Smart Cards, etc.
Survey data from TowerGroup says that users of
wireless financial services in World Regions will grow at a rapid pace,
reaching 35 million in North America and 77
million apiece in Western Europe and Asia
Pacific by 2005. The analyst reports indicate that any FSP cannot afford to
ignore the new channel. However, the question is what services to mobile enable
and how to mobile enable. Will there be sufficient ROI on the investment made
in the wireless applications? In the short term, it appears that profitable ROI
may not be there. However, it is important to invest now in this new
communication channel to the customers. An important reason is that, wireless
is not only going to take a share of the financial market its going to expand
the market as well. Customers, who are going to be more mobile in future,
cannot ignore the value of all-time banking services.
M-Commerce Value Chain
In any relationship between a customer and a business,
there are three levels. The first level is related to the content
provisioning about the business. This may be about the services offered by
the business or about the specific service that the customer is already
subscribing or buying from the business.

The second level is the transactional level, where
the customer has the option of initiating a business transaction with the
business or vice-versa. Growing to this level on a new channel of communication
requires a confidence about the security and authentication on both sides.
Also, both parties need to be confident about the stability of the channel.
The third level is the Relationship building when
both the customer and the business are confident of each other as well as
channel; both have experienced the transactional level to some extent.
In the financial services scenarios, customers getting
financial information on the hand held devices over wireless links, i.e., level
one is already a reality. Any FSP who has not reached this level is well
advised to start the wireless service.
Any FSP who has not reached Mobile
Content Provisioning level is well advised to immediately start the service.
One lesson of dot com burst was that one should exercise
caution while starting any technology based channel. Too much of caution in the
M-Commerce world may, however, lead to huge loss in revenues and also, what is
more dangerous, loss of customers to competitors who are more tech savvy in the
eyes of the customers.
The FSPs have to graduate to the second level quickly. The
second level is more difficult as it involves actual money changing hand in
each contact with the customer. It reduces the total cost of the transaction
for the FSP. However, it is more difficult to achieve because of security and
limitations of the devices. We understand that by end 2002 this level will be
attained by most of the financial institutions. However, the profitability may
require adoption by consumers in large numbers.
The ultimate goal of all FSPs, is to enable single
click transactions, live advice, location specific transactions, personal
mobile advertising and third party sales from the mobile device. This level
will require mobile applications and infrastructure that guarantees more
security, customization, location-based actions, time sensitivity,
device-neutrality and easy of action. The FSPs would be able to graduate to
this level within a year, i.e., by the start of 2003. Although the schedule
given here looks tight, we believe that the investments already made by the
Wireless Service Providers (WSP) in the infrastructure will require them to
search for services that can lead to customer ownership. In their search the
WSPs will have to hit on the financial services to get the ROIs. The FSP anyway
will strive to move up the value chain of the m-Commerce. This interplay of
WSPs and FSPs will create more value for money for customers, as they will get
the benefits and convenience of wireless banking on a continuous basis. Initial
revenues, however, will be reaped by the WSPs. As per a Gartner prediction last
year, WSPs will be the real beneficiaries of
the financial data services. For FSPs the wireless
delivery channel only adds to the total cost. FSPs are actually in a catch-22
situation. They have to invest in non-paying wireless services or else they
will be at a considerable competitive disadvantage. This situation will
continue till the end of this year. However, we believe that 2003 is the year
of wireless financial services.
Given the scenario described above what should be the
strategy of the FSPs in adapting to the wireless technology.
Success Strategy
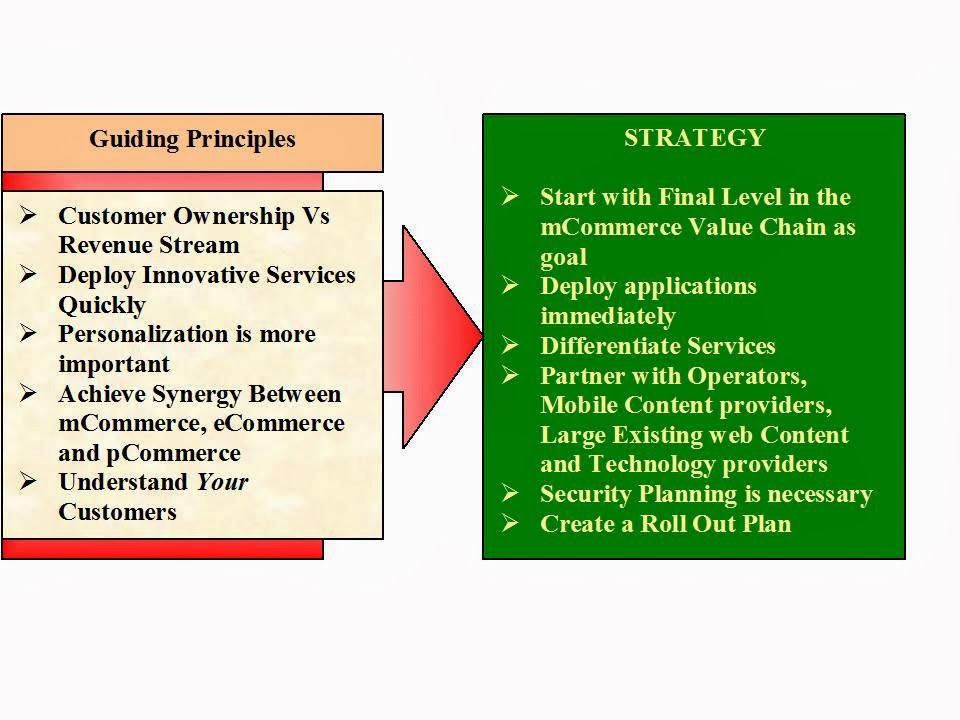
Before defining any grand strategy, it is imperative to
understand the guiding principles that should drive that strategy. The importance
that the FSPs should give to customer retention and ownership should be more
than that given to revenue stream. The applications need to be innovative and
should be quickly deployed. Any service provided to the customers on mobile
devices should be personalized as the mobile device is considered very personal
especially in Asian and Japanese geographies. FSPs should strive to achieve
synergy between physical, electronic and mobile commerce. This synergy should
create a holistic strategy for the FSP.
The basic point is that the strategy should be geared towards the
specific customer profiles of the FSP. It should be mentioned that unique
profile of the customers for the specific FSPs is a major factor affecting the
mobile strategy.
We propose at the broad level the strategy in embracing
mobile technologies for the FSPs. The FSP should start with a goal of achieving
the highest level in the mCommerce value chain. Rather than waiting for
markets, technologies and wireless services to improve, it is imperative that
applications should be deployed quickly. Taking care of competition, as far as
possible, differentiate the services. Continuous innovation in differentiation
is the crux of the matter.
The FSP should start with a goal of achieving the highest level in
the mCommerce value chain.
Most important point in the strategy is the collaboration
that should be achieved with all players across infrastructure value chain.
This includes tie-ups with Operators, Mobile Content providers, Existing Web
Content providers and technology providers.
However, the weakest link in the whole process, i.e.,
end-to-end security, should be properly planned. This planning may require
readiness to pay for security breaches.
Taking all of these things into account a Roll Out plan of
applications at each point of the value chain should be made and executed.
Conclusions
FSPs cannot afford to ignore the wireless channel to the
customers and employees. The channel will require services to be offered to the
customers. The levels of value defined for mCommerce starts with the
information provisioning and ends at the mobile Customer Relationship
Management (mCRM). By the end of this year, most of financial institutes would
have moved up to the second level of transaction-enabled services. We believe
that by 2003 the mCRM will provide the key competitive advantage to FSPs.
A Roll out plan of financial applications keeping the
above scenario in consideration is the major decision that FSPs need to take
NOW.
